Progress in standard.site validation
12 January 2026
A few days ago I published a simple validation tool for standard.site, which is a proposed standard for announcing long-form content on the ATProto network. (I explained what this is about in a previous post.)
My tool is relatively simple: you paste in the URL of one of your posts or articles (what standard.site calls a "document") and press a button. The server downloads your post and follows the chain of metadata to see if everything is in order. This is a simplified diagram:
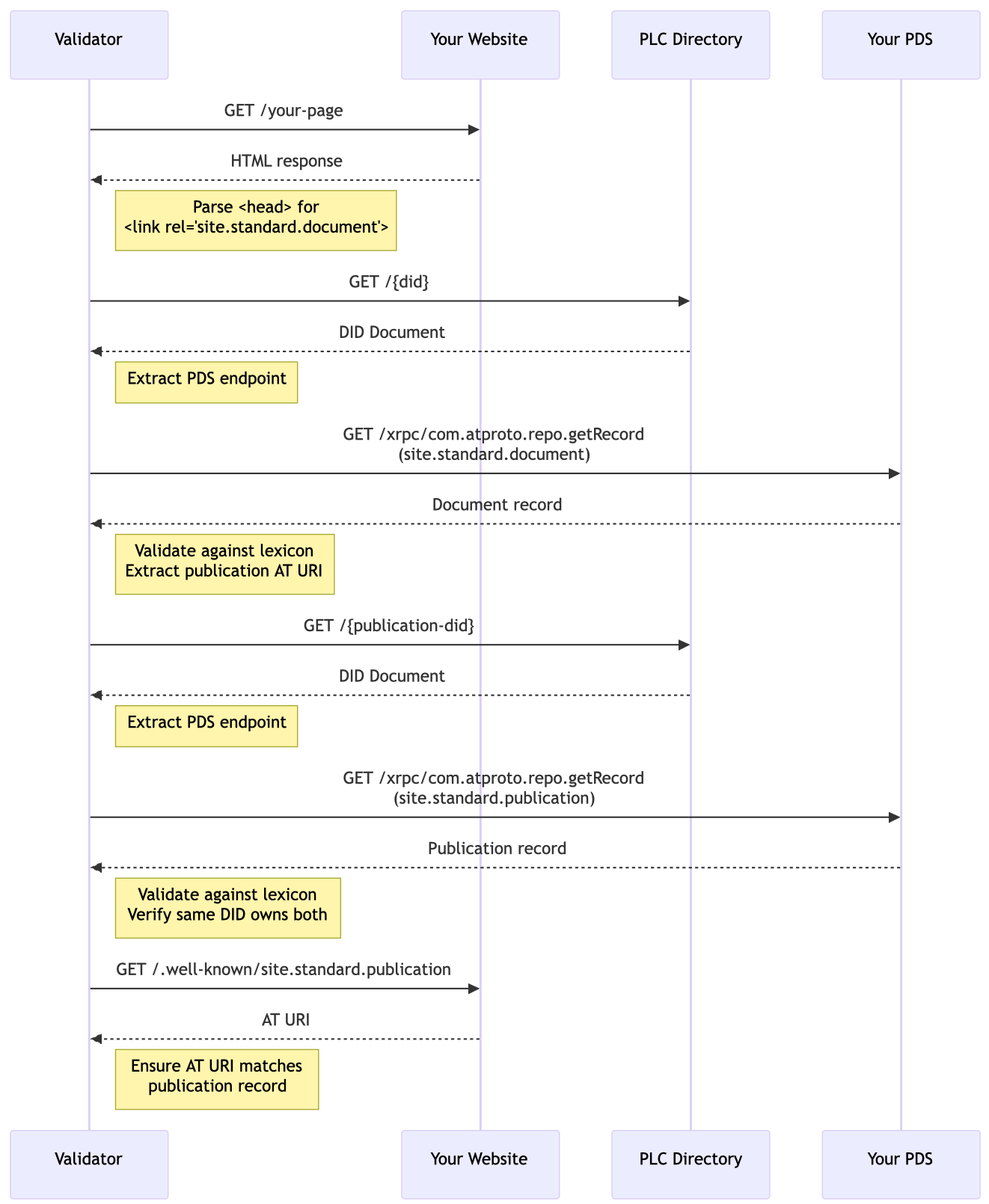
For a number of sites that publish standard.site records, this validation fails early in the process. One of the most commonly-overlooked requirements is adding the <link> tags to the HTML posts themselves, an important protection against somebody creating fake or incorrect records for webpages that you authored. My validator is not an appview and doesn't have an omniscient view of which records might correspond to your blog post. It relies on this <link> as its entry point to find all the other information. Until you address this (somewhat boring) detail it can't tell you anything about whether the records on your PDS are in good shape.
Depending on how your website works this requirement can be somewhat tricky to implement. In the good old days of RSS it was simple: the blog post comes first, and then you take the blog's URL and put it in the RSS feed. There is a simple order of operations. In this case we have a circular dependency: the AT record needs to know the URL of the blog post but to publish the blog post we need to know the at:// URI, including the record key. The bad news is that you can't just assign any old record key. It has to be a TID, one of these special ATProto timestamp strings that looks like 3mbo2wjotu52p. The good news is that these are always assigned client-side. As I see it you have two options:
- When building or publishing a new post, generate a valid TID for "now", potentially using a library. Insert this into the
at://URL for the document, and ensure you use this rkey when pushing the site.standard.document record to your PDS. - Post the standard.site record and let your ATProto client auto-assign a key. Query your PDS to figure out what key it chose and insert the
at://URL back into your HTML document.
I chose the first option. Since my site generator is written in Go it was easy to use the existing library to create a suitable TID.
When I started thinking about this validator I had hoped for a minute that it would be possible to do it entirely in client-side JS, since the xrpc endpoints used by PDSes are designed to be queryable this way. Unfortunately CORS would have prevented me reading the required resources from the target website in many cases so I ended up just doing it server-side.
Now, there is another perspective to validation that's very important. Imagine you're writing an appview that's scouring the firehose for standard.site records and you want to know which ones you can trust. This problem is backwards from how my validator works—you're starting from the record from the PDS, then checking the URL. I know that Filippo Valsorda is working on this for his appview—if you are aware of any other implementations please let me know!
These problems are reasonably different. If you're trying to implement the spec for your website and you accidentally mess up the format of your record then the schema won't validate and it will be (I assume) invisible to appviews. For troubleshooting purposes it's easier to figure out what's going on when we start from the HTML. Also, this way I don't have to run an appview. This is great because I don't want to pay for a server that's handling zillions of messages.
In the course of our experiments Filippo and I have noticed a couple of interesting edge cases. He identified that there's nothing inherently stopping a document record from one repo (think "user") pointing to a publication record belonging to another repo. If verifiers didn't pay attention to this then it could be abused—rather like if someone else could insert their posts into your RSS feed. I decided to handle this in my validator by ensuring that the repo matches for both records since I can't think of a legitimate reason why they wouldn't.
In the current version of the standard.site description there is also an assumption that a given domain (or subdomain) will only contain one publication, so you can place a single verifying record in an origin-scoped .well-known file. My website trivially breaks that assumption: I separate my posts into three blogs hosted at paths /b/scb, /b/to and /b/tt. If I have three at:// URIs corresponding to three publications, what should I put at https://octet-stream.net/.well-known/site.standard.publication?
To my knowledge there have been two discussions about this on Bluesky. In the first thread the favourite idea was to insert the publication's path component (e.g. /b/scb) when looking up the .well-known file. For example: https://octet-stream.net/.well-known/b/scb/site.standard.publication. In a later thread, Filippo suggested it would be better to flip that around to https://octet-stream.net/.well-known/site.standard.publication/b/scb. My site now exposes those paths. My validator will also check this path as a backup if the publication URL has a path component. I'm treating this as defacto valid until there is an official update to the standard.site website.
Overall, lots of fun. Please kick the tyres on the validator and let me know if you have any trouble.
Serious Computer Business Blog by Thomas Karpiniec
Posts RSS, Atom