This blog is on ATProto
5 January 2026
This blog and its posts are now on ATProto, the data backend that powers Bluesky. To what end, I couldn't say just yet. I'm just playing around. This didn't involve any changes whatsoever to the website that you're looking at[1]. It just means that when I publish a new post I also write a new record into my Personal Data Server (PDS) which includes the post's title, publication timestamp, and a URL. This gets slurped off by ATProto relays that subscribe to me and if there's anybody who cares about my posts, they get to find out about it more or less in realtime.
ATProto is a bit weird. It's powered by something called the firehose, which is essentially an RSS feed for every record change that occurred on every PDS. If you are interested in finding new blogs or new blog posts, you can effectively filter the firehose to subscribe to notifications for all of the blogs ever. Now, if your goal is to subscribe to a few of your mates' blogs then handling all this data isn't very appealing. This isn't something you're going to do directly as an end user; rather it's a data stream that can be used to build a webapp running on a big server. Users of that app can then read, discover, search, and subscribe to the things that matter to them. The big server handles the firehose and the users get the benefits of a backend that can see "everything" on the social network.
If you want to start writing new kinds of data into your PDS (such as blog posts) then you don't need permission from anyone. Different data formats are namespaced into schemas called lexicons and anybody is free to define their own. The trickiest part is coordination; if you want to find all the blog posts on the firehose, then everybody needs to agree on what schema represents a blog post. Some folks have recently had a go at fixing that: standard.site. This is a pair of lexicons for declaring a "publication" (e.g. a blog) and a "document" (e.g. a blog post). They are actually incredibly simple data structures. All you have to do is fill out the fields, pop the record into your PDS, and now everybody can see it. So long as your record matches the schema it can be discovered and used by any apps that are looking for data in that format.
Using the excellent tool pdsls.dev, here's what my published entries look like. This blog is represented by a publication. Then, each post is its own document with a backreference that points back to its parent publication via a special at:// URL.

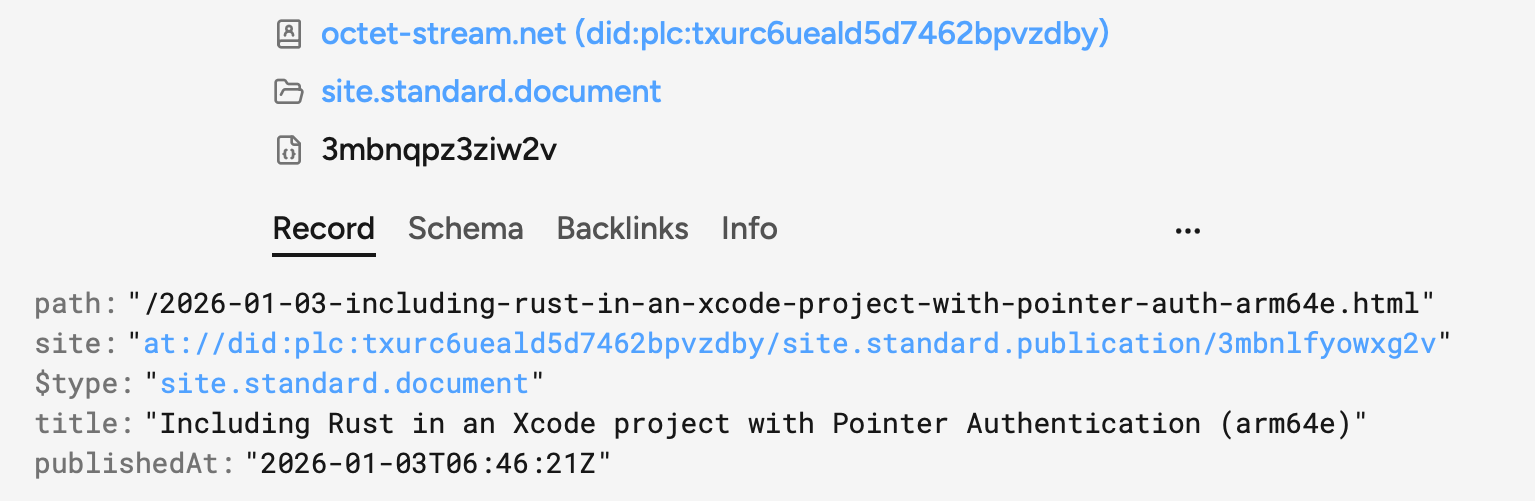
If you compare the document lexicon with mine, you'll notice that I've left out something important (but optional)—the content of the post. This isn't an attempt to be difficult or goofy (like RSS feeds that only contain the first paragraph). In truth everybody's still figuring out the best way to represent content. I author my posts in HTML but it's not clear that anybody benefits if I jam HTML in there. The content fields are of more crucial importance for AT blogging sites like leaflet.pub or pckt.blog where the idea is that your PDS record is your one and only source of truth for the content of your post. This is not so much the case for people like me who are trying to backfill AT metadata for a blog that primarily exists as an HTML website. From discussions on Bluesky I can see that I'm not the only one in this boat.
Already there is a wonderful variety of site.standard.document records showing up, some of which you can browse through here on the UFOs website.
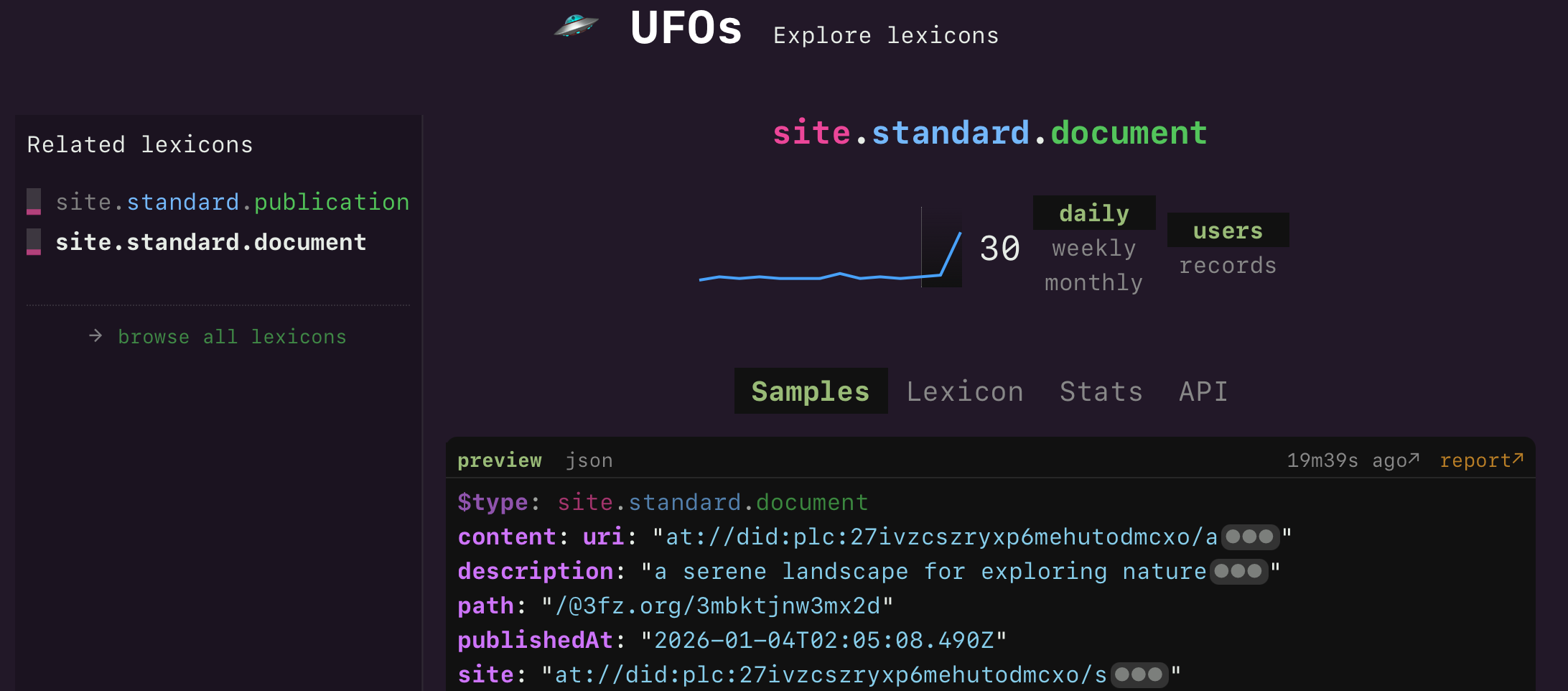
So already we have a little divergence here—some people are publishing entire posts and this is their primary method of distributing content. I am merely publishing links, and the benefit (if any) to AT users is discovery and announcement of new posts. Anyone who is making an app that consumes these records is going to have to decide what their purpose is and handle the variance in record content accordingly. I won't rule out adding some sort of text content in the future but it's extra work and it's not clear to me yet whether there's any point.
If you're wondering how I did it, well, I have no code to share unfortunately. The static site generator that builds this blog is a homegrown mess of Go and TOML, which made it quite easy to hack in an extra bit to emit the metadata required for the AT records. I then wrote a second utility that shells out to goat to check which records are already present on my PDS, then does whatever CRUD operations are required to bring it into sync. It's pretty horrific but it demonstrates the core promise of ATProto: I didn't have to liaise with anyone or use any special software to participate in publishing new records. I just had to follow the schema and ship it off to my own PDS, and it's live.
- Update 9 Jan 2026: At first I accidentally skipped over the "Verification" part of standard.site, which requires that you add a corresponding
<link>tag to each document and set up a.well-knownpath to verify the publication. I have now done that. So I was wrong—modifications to this website were in fact required. ↩︎
Serious Computer Business Blog by Thomas Karpiniec
Posts RSS, Atom